Membuat Web Scraper dengan Ruby (Output: HTML)
Table of Contents
PERHATIAN!
Data yang penulis gunakan adalah data yang bersifat free public data. Sehingga, siapa saja dapat mengakses dan melihat tanpa perlu melalui layer authentikasi.
Penyalahgunaan data, bukan merupakan tanggung jawab dari penulis seutuhnya.
Prerequisite
ruby 2.6.6 rails 5.2.4 postgresql 12.3
Pendahuluan
Web scraping adalah teknik mengambil atau mengekstrak sebagian data dari suatu website secara spesifik, spesifik dalam arti hanya data tertentu saja yang diambil. Script atau program untuk melakukan hal tersebut, disebut dengan web scraper.
Objektif
Catatan kali ini saya akan mendokumentasikan proses dalam membuat web scraper dengan tujuan untuk mengambil data nama-nama dosen yang ada pada website resmi Biro Akademik Universitas Mulia Balikpapan yang ada pada halaman ini.
Hasil yang akan di dapatkan dari script yang akan kita buat adalah file html berisi daftar nama-nama dosen beserta nidn dalam bentuk tabel.
Penerapan
Langkah awal adalah persiapkan direktori untuk proyek.
Saya akan beri nama ruby-web-scraper-dosen.
Biasakan untuk memberi nama proyek tidak menggunakan karakter spasi.
$ mkdir ruby-web-scraper-dosen
Kemudian masuk ke dalam direktori proyek.
$ cd ruby-web-scraper-dosen
Buat file dengan nama Gemfile. dan kita akan memasang gem yang diperlukan di dalam file ini.
!filename: Gemfile
source 'https://rubygems.org'
gem 'httparty', '~> 0.18.1'
gem 'nokogiri', '~> 1.10', '>= 1.10.9'
gem 'byebug', '~> 11.1', '>= 11.1.3'
Setelah memasang gem pada Gemfile, kita perlu melakukan instalasi gem-gem tersebut.
$ bundle install
Proses bundle install di atas akan membuat sebuah file baru bernama Gemfile.lock yang berisi daftar dependensi dari gem yang kita butuhkan –daftar requirements–.
Sekarang kita akan membuat aktor utamanya. Beri nama scraper.rb.
!filename: scraper.rb
# daftar gem yang diperlukan
require 'httparty'
require 'nokogiri'
require 'byebug'
def scraper
# blok ini bertugas untuk mengambil data dengan output berupa variabel array
target_url = "http://baak.universitasmulia.ac.id/dosen/"
unparsed_page = HTTParty.get(target_url)
parsed_page = Nokogiri::HTML(unparsed_page)
dosens = Array.new
dosen_listings = parsed_page.css('div.elementor-widget-wrap')
dosen_listings.each do |dosen_list|
dosen = {
nama_dosen: dosen_list.css("h2")[0]&.text,
nidn_dosen: dosen_list.css("h2")[1]&.text
}
if dosen[:nama_dosen] != nil
dosens << dosen # dosens, variable array yang menampung data para dosen
end
end
# aktifkan byebug apabila diperlukan
#byebug
# blok ini bertugas untuk membuat file html
File.delete("daftar_dosen.html") if File.exist?("daftar_dosen.html")
File.open("daftar_dosen.html", "w") do |f|
f.puts '<!DOCTYPE html>'
f.puts '<html lang="en">'
f.puts '<head>'
f.puts '<meta charset="UTF-8">'
f.puts "<title>Daftar Dosen Universitas Mulia (#{dosens.count} dosen)</title>"
f.puts '<style>table,th,td{border:1px solid black;border-collapse:collapse;}</style>'
f.puts '</head>'
f.puts '<body>'
f.puts '<table>'
# perulangan ini bertugas menginputkan data dosen ke dalam tabel row
dosens.each do |dosen|
f.puts '<tr>'
f.puts "<td>#{dosen[:nama_dosen]}</td>"
f.puts "<td>#{dosen[:nidn_dosen]}</td>"
f.puts '</tr>'
end
f.puts '</table>'
f.puts '</body>'
f.puts '</html>'
end
puts "TOTAL DOSEN: #{dosens.count} orang"
end
scraper
Kemudian, jalankan dengan perintah,
$ ruby scraper.rb
Apabila berhasil, akan terbuat sebuah file dengan nama daftar_dosen.html.
Coba buka file tersebut dengan Browser.
Hasilnya akan seprti ini.
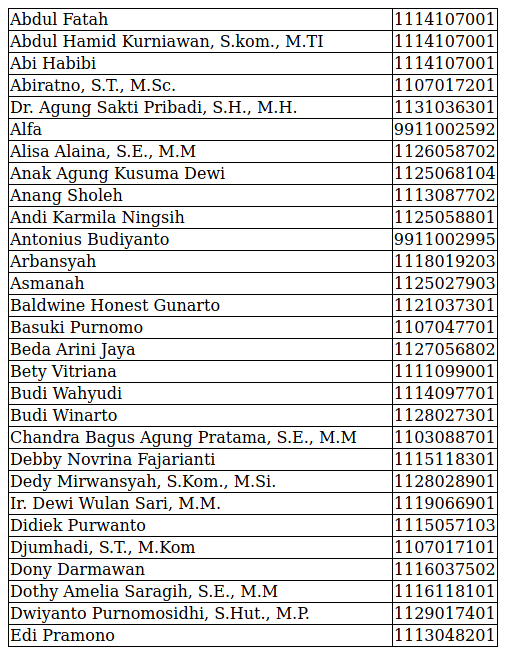
Gambar 1. Tabel daftar dosen hasil web scraping
Selesai!
Demonstrasi Video
Referensi
-
It’s Time To HTTParty!
Diakses tanggal: 2020-06-12 -
nokogiri.org
Diakses tanggal: 2020-06-12
